Abstract
We propose MVDream, a multi-view diffusion model that is able to generate geometrically consistent multi-view images from a given text prompt. By leveraging image diffusion models pre-trained on large-scale web datasets and a multi-view dataset rendered from 3D assets, the resulting multi-view diffusion model can achieve both the generalizability of 2D diffusion and the consistency of 3D data. Such a model can thus be applied as a multi-view prior for 3D generation via Score Distillation Sampling, where it greatly improves the stability of existing 2D-lifting methods by solving the 3D consistency problem. Finally, we show that the multi-view diffusion model can also be fine-tuned under a few shot setting for personalized 3D generation, i.e. DreamBooth3D application, where the consistency can be maintained after learning the subject identity.
方法

Figure 2: Illustration of the overall multi-view diffusion model. During training, multi-view images are rendered from real 3D models to train the diffusion model, where we keep the structure of the original text-to-image UNet by making two slight changes: (1) changing the self-attention block from 2D to 3D for cross-view connection (2) adding camera embeddings to the time embeddings for each view. During testing, the same pipeline is used in a reverse way. The multi-view diffusion model serves as 3D prior to optimize the 3D representation via Score Distillation Sampling (SDS).
理解几个概念
Score Distillation Sampling
为什么选择SDS而不是直接用Nerf的few-shot变种之类的?
原因: While our diffusion model’s multi-view images appear consistent, their geometric compatibility isn’t assured.
看来对于这类3D问题,用由
3️⃣
![]() DreamFusion: Text-to-3D using 2D Diffusion
提出的SDS似乎是现在比较主流的解法。
DreamFusion: Text-to-3D using 2D Diffusion
提出的SDS似乎是现在比较主流的解法。
DreamBooth3D
Inspired by DreamBooth (Ruiz et al., 2023) and DreamBooth3D (Raj et al., 2023), we also employ our multi-view diffusion model to assimilate identity information from a collection of provided images and it demonstrates robust multi-view consistency after such a few-show fine-tuning. When incorporated into the 3D generation pipeline, our model, namely MVDream, successfully generates 3D Nerf models without the Janus issue. It either surpasses or matches the diversity seen in other state-of-the-art methods.
如何从少数example图片吸收identity information的?
Multi-face Janus Problem

比较常见的2D lift到3D的两种问题。
times embeddings
这个是指diffusion process的time step的一个positional embedding?
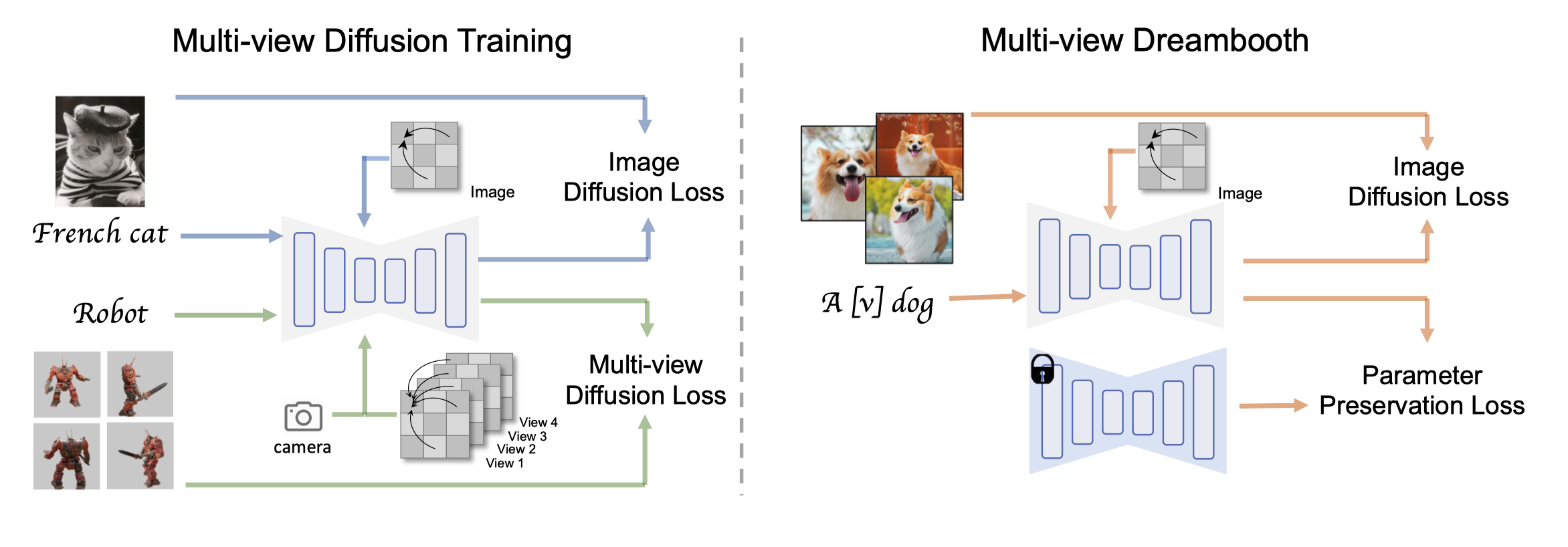
Figure 3: Illustration of the training pipeline of MVDream. Left: Training of Multi-view diffusion (MVDiffusion), it is mixed trained with two modes: with the 2D attention (upper) and 3D multi-view attention (lower). Details in Sec. 3.2.3. Right: Training of MVDreamBooth, it takes the pre-trained MVDiffusion model, and then finetuned with the mode of 2D attention and a preservation loss. Details in Sec. 3.4.
- 这是abstract中最后所言的,利用Dreambooth的想法将对象的identity 用finetune的方式去personalize
-
2D attention是怎么和3D attention一起训练的?如何切换mode?
- 都是用SD原来的module,只是把 frames 改为batch 的可能性比较大,具体怎么样不太清楚。
- 3D multi-view attention和 3D self attention是一回事吗?
- 用preservation loss保证不会出现catastrophic forgetting
相关著作
- Dreamfusion-IF
- Magic3D-IF-SD
- Text2Mesh-IF
- ProlificDreamer